I used to have this confusion when I study a basic concept. I would understand it very well, but when I tried to recap it in my mind, there was always this gap I couldn’t fill. In this blog, I’ll try to explain the confusion I had while refreshing my memory of mini-batch SGD. If you’re looking for an explained tutorial for mini-batch SGD, this might not be the place.
When I go back and watch a YouTube video or my tutorials, I feel like that was an obvious point, how could I miss it? But what can I do, it is what it is. Our minds are not like trained ML models, right? We forget things even after rigorous training. But then I also think that being able to forget things is one of our greatest powers; otherwise, we would all be living in sorrow all the time.
Anyways, enough of my thought process, let’s jump into SGD.
The main reason for the confusion is that, when I learned SGD, I first learned the equation:
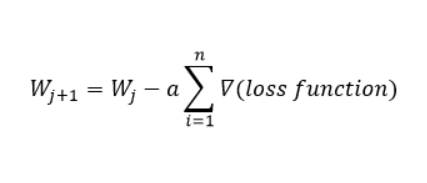
Here, Wj+1 is the updated weight vector, ‘a’ is the learning rate, and the last part is the gradient of the loss function. While writing our codes in Python, we don’t have to think about any of this, right? We only have to tell the algorithm how we’re planning to alter the learning rate, number of points in a mini-batch, or number of epochs. My confusion here was the following: When does these weights get updated exactly, how each data point is taken into the formula, and how much will the weight get updated after each iteration?
Now I know the answers, or at least I think I do. In gradient descent, at first, W0 is randomly created. Then a single data point is inserted into the equation to calculate the gradient of the loss function. The values of our random weight vectors (since loss function is calculated using weight vectors) and the data points (a single data point) are given to calculate the numerical values of the gradient, and then this value is set aside. The next data point is inserted to calculate the next gradient and is added to the previously set-aside value (the numerical value of data point is added after applying the gradient function. This is a common confusion that usually arise as we are not seeing it real time). This process is repeated until all the points in the training data set are completed. Only then is the weight vector updated. This is an extremely time-consuming process, right? That’s why SGD was introduced. In SGD, we update the weights after a set of gradients are calculated. Let’s say we have 1000 data points. Then, after 10 data points are added in, we update the weight vector. Earlier, we had to sum the gradient of all 1000 data points to complete one iteration (update weight vectors). Here, the weights get updated 100 times after completely going through the data set once. This is one epoch.
To sum up, the gradient of the loss function needs both weight vectors and data points to calculate it. The summation is calculated over all the n data points in gradient descent and for a small batch size in mini-batch SGD.