Understanding the problem in hand is ‘the’ most important thing in data science. You might know dozens of algorithm, thousands of libraries, tons of visualization tool, numerous feature engineering techniques or five different programming languages. But if you have not embraced the business objective like the primary class algebra, there is no point.
You may be wondering why I titled it precision over recall and writing random things. This so called revelation came while I was thinking about why precision is chosen over recall for credit card fraud detection problems.
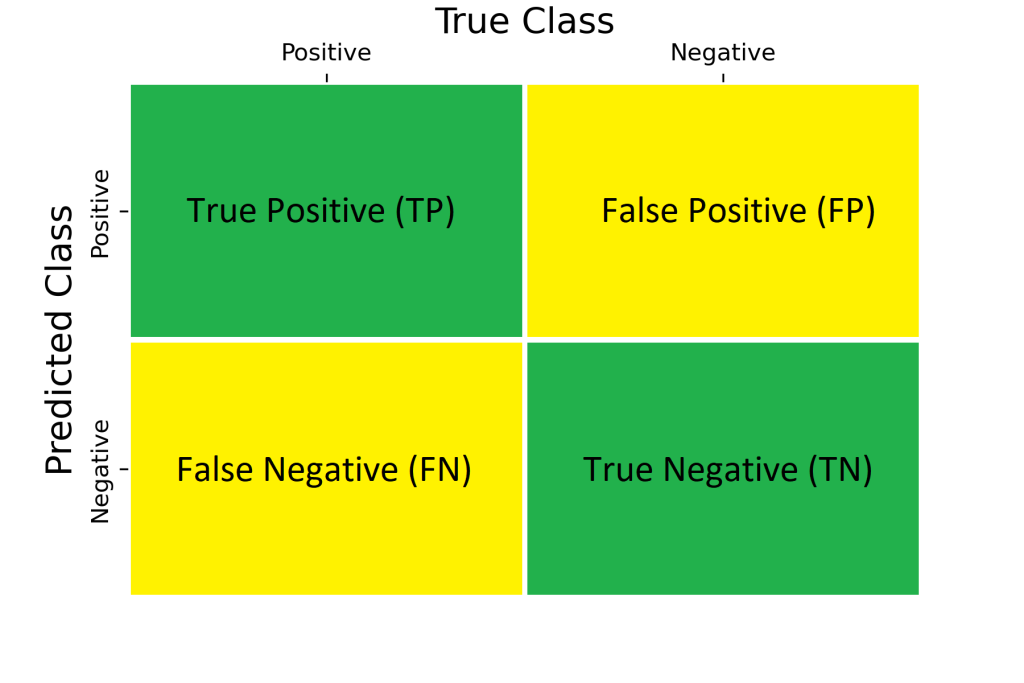
Before jumping into my thoughts, let me quickly refresh your memory on precision and recall first. Let us say there where a total 1000 training points in which 900 where legitimate transactions and 100 where fraud. Out of which, 850 predicted as legitimate correctly and 75 predicted as fraud correctly. In our example, positive means it is legitimate and negative means fraud. Then, our confusion matrix will looks like,

The TP, TN, FP and FN are,
Precision=TP/(TP+FP)=0.97
Recall=TP/(TP+FN)=0.94
Please remember that the numbers are taken for example and do not compare it with real world cases. Anyway, our discussion topic was, which among the two matrices should we increase for the problem in hand. To be frank, when I was learning this concept, I thought isn’t that both similar. I mean, we actually want is to increase both TP and TN to maximum right? Well, the real world is not that simple it seems, you have to choose among them sometimes. Do you want to penalize False Negative more or False Positive more? Now the question is, which one?
Let’s understand both scenario here. What does increasing precision or recall actually means. Increasing precision means, decrease the number of false positive as much as possible. A false positive means, the model predicted a fraudulent transaction as a legitimate one. Here bank loses money. But in recall, the model tries to minimize false negative. Or, the ones where model predicted a legitimate transaction as fraud one, which bank can afford even though the customer might think differently. I hope you got the point I was trying to explain, he key point is understanding the objective and then building the machine learning pipeline according to that.
Let’s wind up with a small example where we want to increase recall. Suppose you have a machine learning model that predicts whether a patient has cancer or not based on various medical tests. If the model predicts that the patient has cancer, the patient will undergo further tests and treatment. If the model predicts that the patient does not have cancer, the patient will not undergo further tests or treatment.
In this scenario, you want to minimize the number of false negative predictions (i.e., patients with cancer who are wrongly diagnosed as not having cancer), even if it means increasing the number of false positive predictions (i.e., patients without cancer who are wrongly diagnosed as having cancer).